In distributed computing, managing resources efficiently across multiple servers or nodes is a common challenge. One of the main problems is how to distribute and retrieve data efficiently, especially as nodes are added and removed. This is where consistent hashing comest into play. Consistent hashing is a strategy used to evenly distribute data across a dynamic set of nodes, ensuring minimal disruption when nodes changes.
What is Consistent Hashing?
Consistent hashing is a distributed hash table (DHT) technique that provides a way to allocate keys (representing data or requests) to a variable number of nodes in a scalable and fault tolerant manner
Terminology
- Node – a server that provides functionality to other services
- Hash Function – a mathematical function used to map data of arbitrary size to fixed-size values
- Key – value generated after hashing, used to map to data in a hash table / map
The key idea is to map both nodes and keys to a a common hash space, typically represented as a circle or a ring. This method minimizes the number of keys that need to be reassigned when nodes are added or removed, making it ideal for dynamic environments like cloud systems, distributed caches, or a large scale distributed databases.
Traditional Static Hashing vs Dynamic Consistent Hashing
In traditional static hash functions, the keys are assigned to nodes using a module operation
node_id = (static_hash(key) % number_of_nodes)The time complexity to locate a node identifier in such hash partitioning is a constant O(1). This is a simple approach to hashing but suffers from major drawback – Node Churn (adding or removing nodes) requires rehashing most of the keys, causing a disruption across the system.
In contrast, dynamic consistent hashing only remaps a small fraction of keys when the number of nodes changes, making the system more scala le and fault tolerant.
Example – Static Hashing
Consider a system with 4 nodes – Node A, Node B, Node C and Node D. We use a simple hash function and modulo operation to map keys to these nodes
- hash(key1) % 4 = Node A
- hash(key2) % 4 = Node B
- hash(key3) % 4 = Node C
- hash(key4) % 4 = Node D
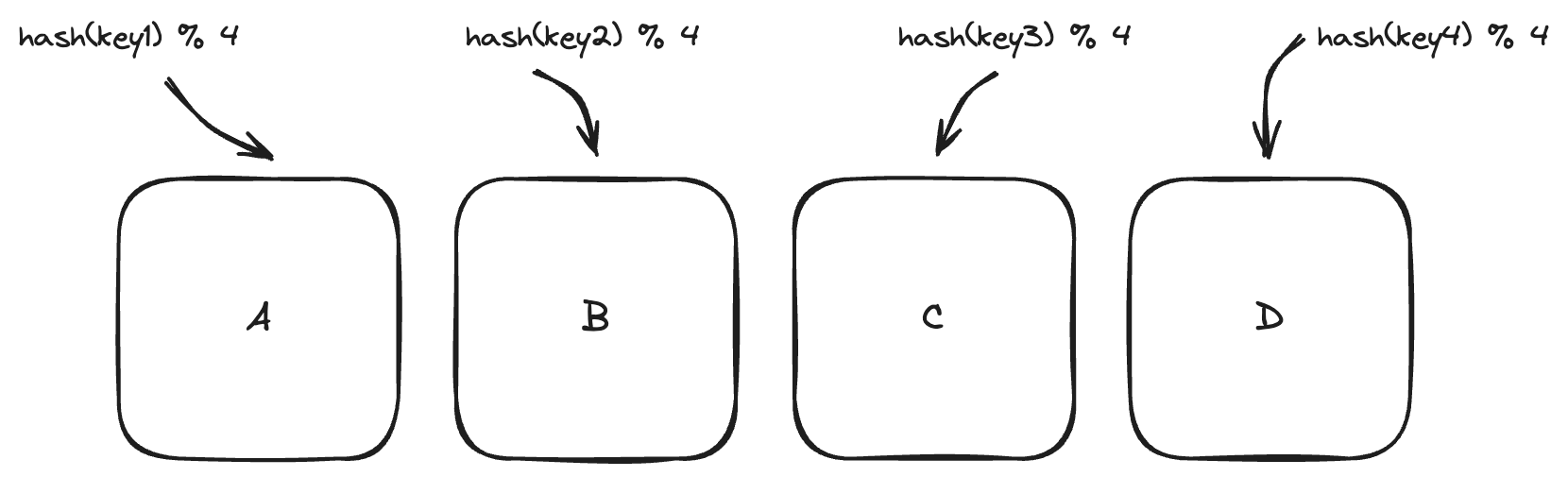
If a new node Node E is added, we now hash with 5 nodes instead of 4. This change causes most of the keys to be reassigned, creating a costly and disruptive redistribution. The same happens when a node is removed.
How Consistent Hashing Works
In consistent hashing, both keys (representing data) and nodes are hashed and placed on a virtual circle or hash ring. The positions on the ring are determined by a hash function that maps both nodes and keys to a large number or space (e.g. 0 to 2^32 -1). A uniform and independent hashing function such as message-digest 5 (MD5) is used to find the position of the nodes and keys on the hash ring. The output range of the hash function must be reasonable size to prevent collisions.
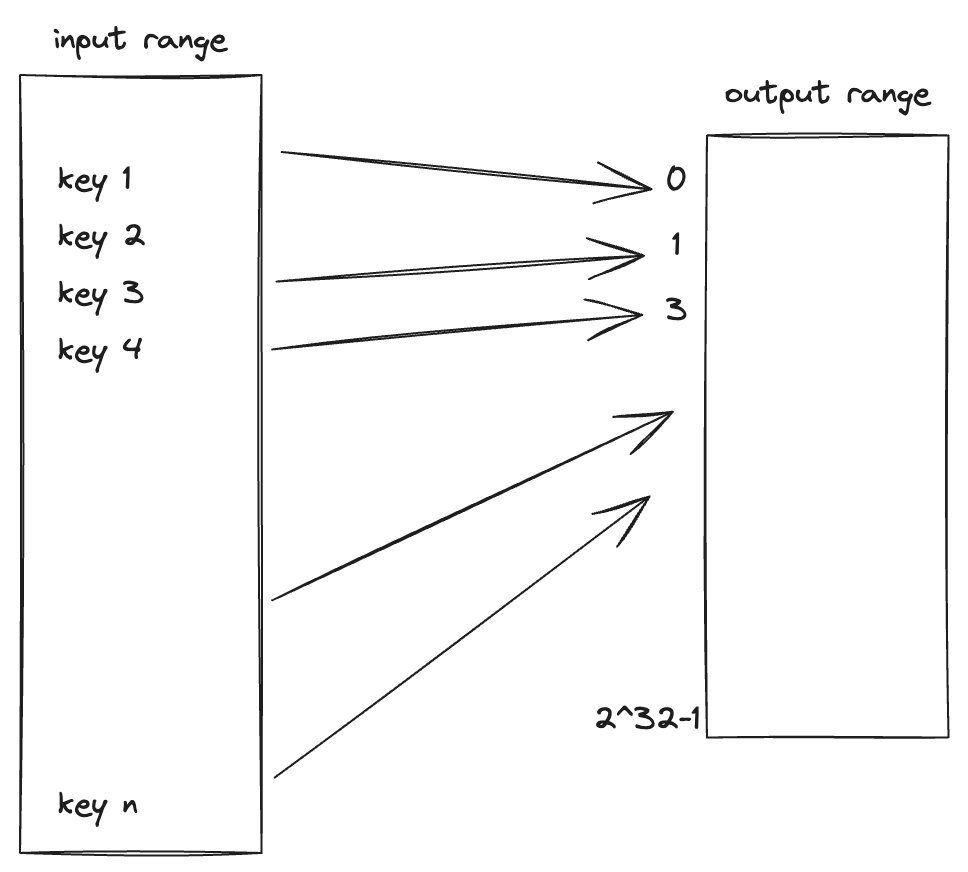
- Assigning Nodes to the Ring – Each node is assigned a position on the ring based on its hash
- Assigning Keys to the Ring – Each key is also assigned to a position on the ring using the same hash function
- Data Assignment – A key is assigned to the first node encountered when moving clockwise around the ring
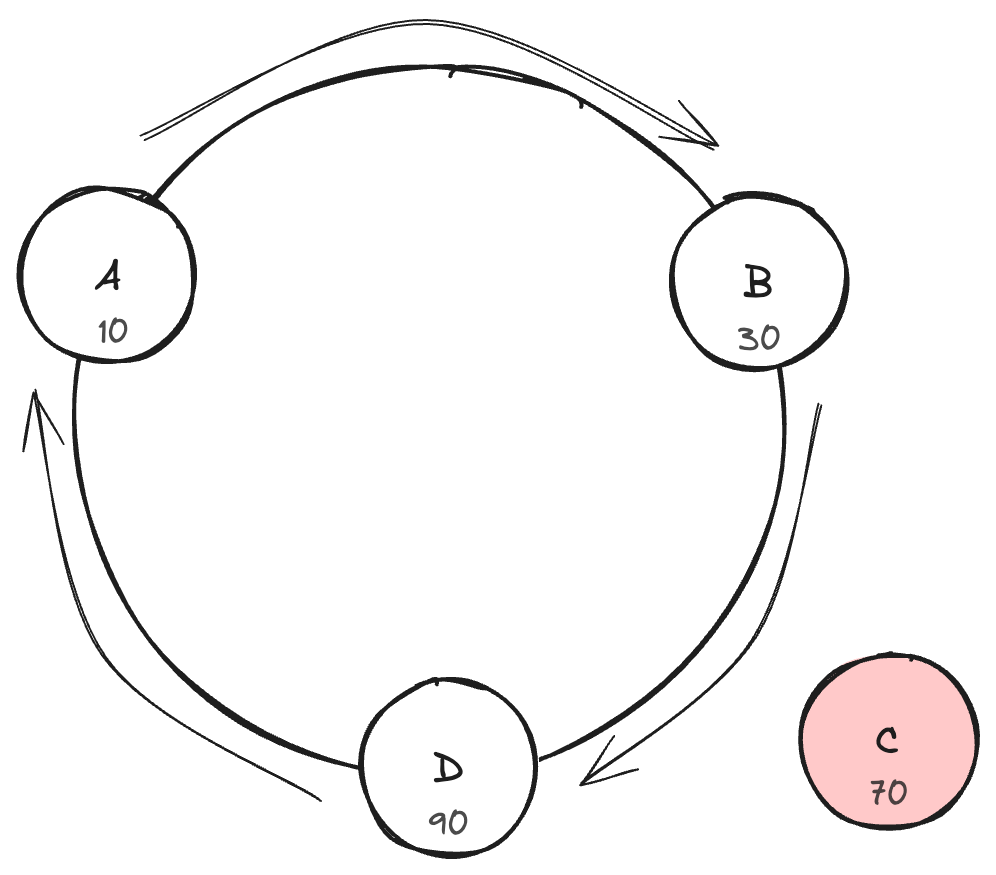
Example – Consistent Hashing with Nodes
Let’s assume we have 4 nodes – Node A, Node B, Node C, and Node D and we hash them into positions on the ring as follows –
- Node A hashes to position 10
- Node B hashes to position 30
- Node C hashes to position 70
- Node D hashes to position 90
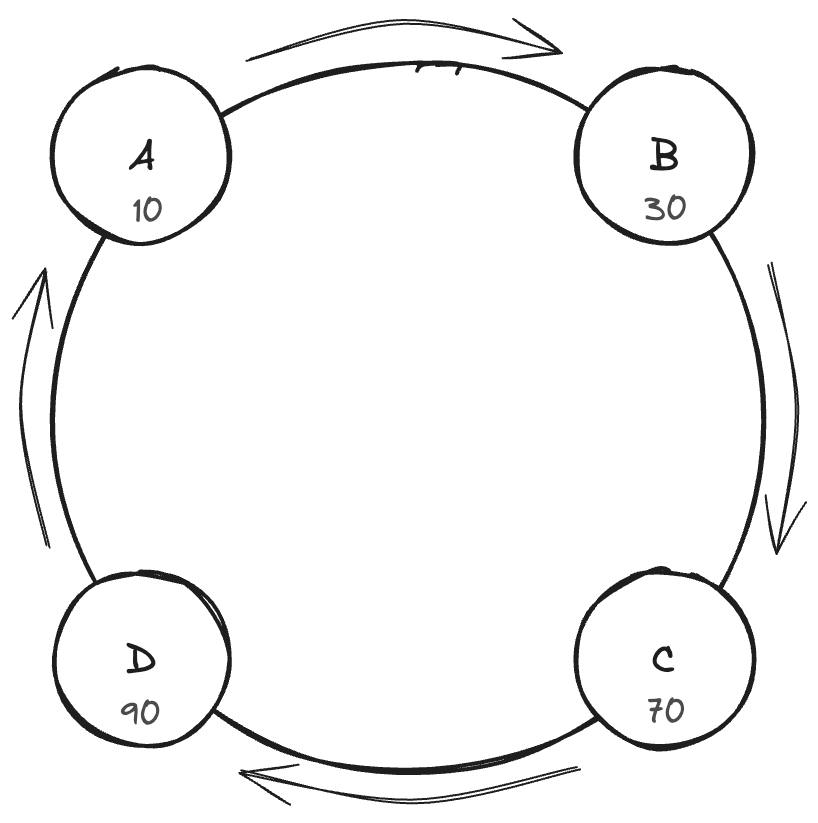
Now, consider the keys that needs to be stored are as follows –
- Key 1 hashes to position 25
- Key 2 hashes to position 55
- Key 3 hashes to position 85
According to the consistent hashing algorithm – (both node and key hash are used)
- Key 1 is stored in Node B (next node clockwise from 25)
- Key 2 is stored Node C
- Key 3 is stored in Node D
Adding or Removing Nodes
One of the key advantages of consistent hashing is that when nodes are added or removed, only a small fraction of keys needs to be reassigned
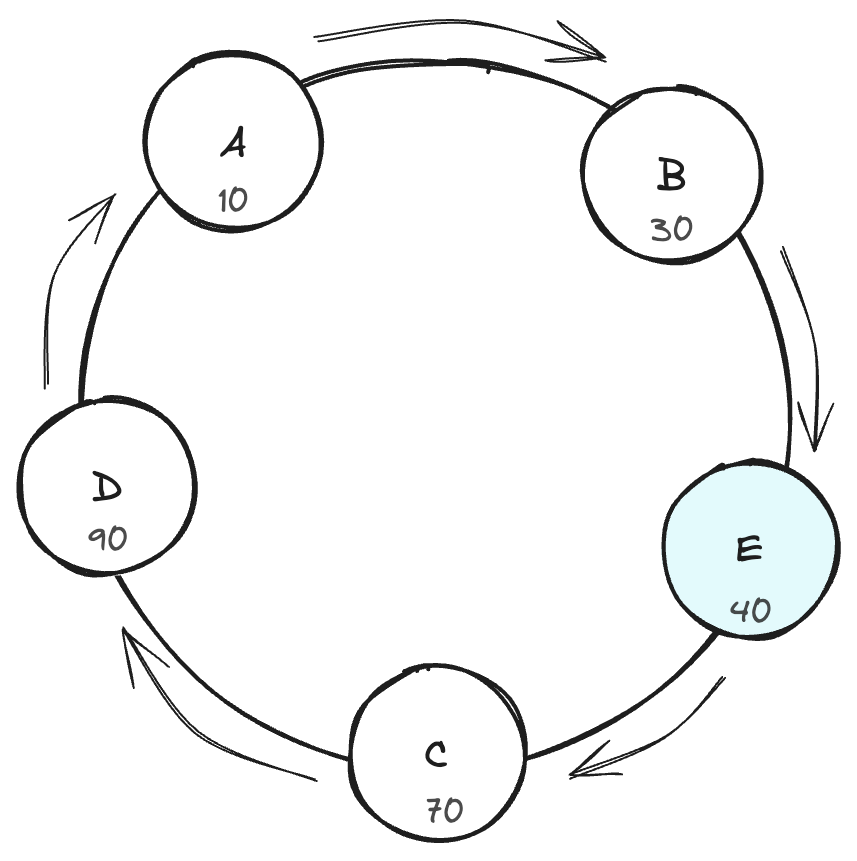
Example – Adding a node
Let’s say we add a new node Node E, and it hashes to position 40, Now –
- Key 2, previously stored on Node C, will move to Node E because Node E is the next node clockwise from Key 2’s position
- All other keys (Key 1 and Key 3) remain unaffected, thus minimizing the reassignment of data.
Example – Removing a Node
If Node C is removed, all keys between Node B and Node D (i.e., Key 2) will now be assigned to Node D. The other keys remain unaffected, limiting the number of keys that need to be reassigned
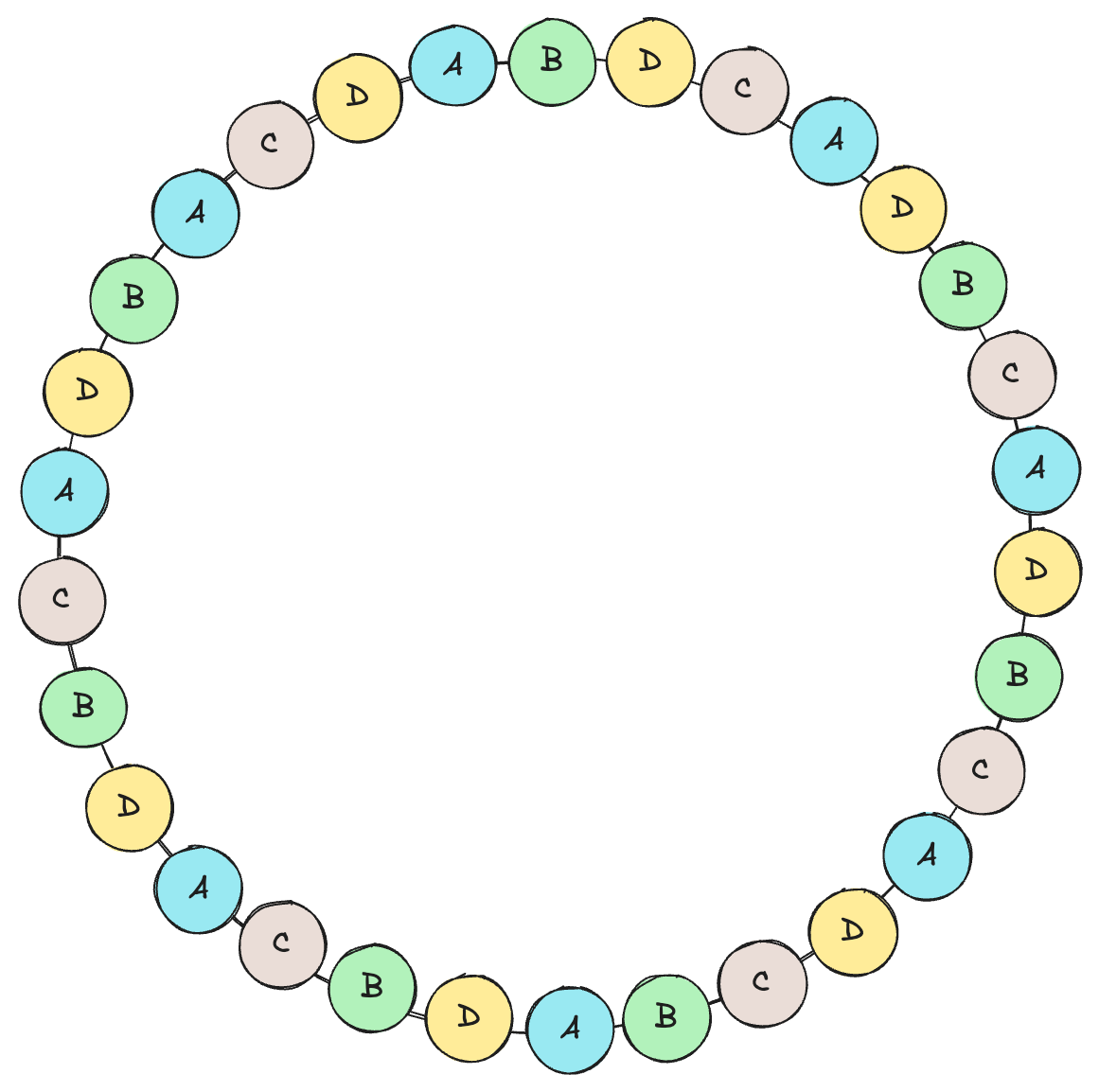
Virtual Nodes (VNodes)
To further improve the distribution of keys across nodes, consistent hashing often uses virtual nodes (VNodes). In this approach, each physical node is represented by multiple virtual nodes that are placed at different positions on the ring (random distribution). This increases the uniformity of key distribution and makes the system more robust against node failures.
Virtual Nodes (VNodes) are a crucial enhancement to the basic consistent hashing mechanism. They solve several key challenges associated with the uniform distribution of data and fault tolerance in distributed systems. Below are the main reasons for using VNodes
- Improving Load Balancing
- Improving Fault Tolerance and Scalability
- Simplifying Node addition and removal
- Handling Heterogenous Nodes
Random Distribution
One of the core benefits of using virtual nodes (VNodes) in consistent hashing is the ability to achieve a random distribution of data across the hash ring. By placing multiple VNodes for each physical node at random positions on the ring, the system ensures that the keys are distributed more uniformly, reducing the risk of load imbalance that may arise due to clustering of keys or nodes. This random distribution helps in ensuring that data does not concentrate on specific nodes, which could otherwise lead to performance bottlenecks or underutilization of resources. This is achived via the use of multiple, unique hash functions.
Additionally, random distribution of VNodes also has a significant impact on partitioning request flow. In distributed systems, clients often send requests for data stored on specific nodes. Without VNodes, a node that stores a popular subset of keys may become overwhelmed with requests. However, with VNodes, the request pattern is naturally partitioned. Since the keys for a single node are distributed across several VNodes, the requests targeting a specific set of keys are also spread out across multiple physical nodes. This effectively reduces hot spots (where certain nodes receive disproportionate amounts of traffic) and ensures that the system can handle high request volumes without performance degradation.
Use Cases
Consistent hashing is widely used in distributed systems to achieve scalability and fault tolerance. Some common use cases include:
1. Distributed Databases– Systems like Apache Cassandra and Amazon DynamoDB use consistent hashing to distribute data across nodes and handle node failures with minimal data redistribution.
2. Caching Systems– Tools like Memcached and Riak use consistent hashing to distribute cache keys across multiple servers.
3. Content Delivery Networks (CDNs)– CDNs use consistent hashing to map content to edge servers and minimize the disruption when nodes are added or removed.
Summary
Consistent hashing is a key technique in distributed computing that enables efficient data distribution and scaling. It solves the problem of massive data reassignment when nodes are added or removed, ensuring that only a small portion of keys are affected. By using a hash ring and techniques like virtual nodes, consistent hashing provides robustness, fault tolerance, and scalability for distributed systems.

Leave a comment